better watchout
better !cry
better !pout
lpr why
santaclaus town
cat >list /etc/passwd
ncheck list
ncheck list
grep >nogiftlist naughty list
grep >giftlist nice list
santaclaus town
who | grep sleeping
who | grep awake
who | grep bad|| good
for (goodness sake) {be good}
Happy christmas everyone.
Sunday, December 24, 2006
Friday, December 22, 2006
On yet another new topic, i'm proud to have the first implementation of Mono.Nat available here. Mono.Nat is a C# implementation of the uPnP protocol implementing just the bits needed to forward a port from a uPnP enabled router to your computer. There are plans to implement the PMP protocol aswell, along with any other port forwarding type protocols that get devised in the future. The idea is that regardless of what kind of router you have, you'll be able to map a port with a 3 (or so) lines of code.
It comes with a code example showing you one way in which to use the code. But it is fairly self explanatory. It's as easy as: natDevice.BeginMapPort(12321, TCP); natDevice.EndMapPort();
If anyone has a NAT enabled router, i'd appreciate it if you could load up the TestClient (in the examples directory) and see if it will map and unmap the 4 different ports. If it does, then all is well. If not, then either tell me what the problem is, or try fix it yourself and send me a patch. It's all good :)
It comes with a code example showing you one way in which to use the code. But it is fairly self explanatory. It's as easy as: natDevice.BeginMapPort(12321, TCP); natDevice.EndMapPort();
If anyone has a NAT enabled router, i'd appreciate it if you could load up the TestClient (in the examples directory) and see if it will map and unmap the 4 different ports. If it does, then all is well. If not, then either tell me what the problem is, or try fix it yourself and send me a patch. It's all good :)
Thursday, December 21, 2006
Wednesday, December 20, 2006
In a similar theme to my last post, i'm going to harp on about a much more useful and not so obvious performance boost i made:
Firstly, consider the following two method signatures:
M1: public static Matrix Add(Matrix matrix1, Matrix matrix2)
M2: public static void Add(ref Matrix matrix1, ref Matrix matrix2, out Matrix result)
From first appearances, which method would you expect to be faster? And why? I'll come back to that in a minute.
Now, the way the code was initially written is that all the logic to add two matrices was contained in M1. So if you called M2, internally M2 would just call M1 and return the result to you. That's fine. It's definitely a good thing to not write the same code in 2 or more methods! This code resulted in the following performance characteristics:
M1 called 5,000,000 times: 500ms
M2 called 5,000,000 times: 750ms
As you can see, contrary to what you might think, M1 was performing significantly faster than M2! Now, the reason why you would expect M2 to perform *much* faster is that passing by ref means that the Matrix struct will not be copied into a new stack frame. Instead a reference to it will be there (which is significantly smaller in size, therefore faster to create). However what was happening is that a reference was being passed to M2, then M1 passed a new copy of the matrix to M1. This meant that all the benefits of using ref were lost.
So, my quick change was to move all the logic to "Add" two matrices into the Matrix.Add(ref,ref,out) method. That way whenever anyone called M2, there would be no copying of structs done, thus potentially making the method much faster. Whenever M1 is called, it then calls M2 internally to do the actual adding, and returns the value then. This way of doing things resulted in the following performance characteristics:
M1 called 5,000,000 times: 720ms
M2 called 5,000,000 times: 200ms
As you can see, M2 is now *much* faster than M1, which is what would be expected when using ref parameters. Also, M1 is now a bit slower, due to the extra overhead of calling M2 to do the adding, but not significantly so.
Just as a reference, heres the same code running under Microsofts XNA:
M1 called 5,000,000 times: 670ms
M2 called 5,000,000 times: 200ms
If i really wanted, i could increase the speed of Matrix.Add(Matrix,Matrix) by writing the adding logic in there aswell, but i don't really want to do that. If you want performance, you'll use the Add(ref,ref,out) option.
The before and after code can be seen here
Firstly, consider the following two method signatures:
M1: public static Matrix Add(Matrix matrix1, Matrix matrix2)
M2: public static void Add(ref Matrix matrix1, ref Matrix matrix2, out Matrix result)
From first appearances, which method would you expect to be faster? And why? I'll come back to that in a minute.
Now, the way the code was initially written is that all the logic to add two matrices was contained in M1. So if you called M2, internally M2 would just call M1 and return the result to you. That's fine. It's definitely a good thing to not write the same code in 2 or more methods! This code resulted in the following performance characteristics:
M1 called 5,000,000 times: 500ms
M2 called 5,000,000 times: 750ms
As you can see, contrary to what you might think, M1 was performing significantly faster than M2! Now, the reason why you would expect M2 to perform *much* faster is that passing by ref means that the Matrix struct will not be copied into a new stack frame. Instead a reference to it will be there (which is significantly smaller in size, therefore faster to create). However what was happening is that a reference was being passed to M2, then M1 passed a new copy of the matrix to M1. This meant that all the benefits of using ref were lost.
So, my quick change was to move all the logic to "Add" two matrices into the Matrix.Add(ref,ref,out) method. That way whenever anyone called M2, there would be no copying of structs done, thus potentially making the method much faster. Whenever M1 is called, it then calls M2 internally to do the actual adding, and returns the value then. This way of doing things resulted in the following performance characteristics:
M1 called 5,000,000 times: 720ms
M2 called 5,000,000 times: 200ms
As you can see, M2 is now *much* faster than M1, which is what would be expected when using ref parameters. Also, M1 is now a bit slower, due to the extra overhead of calling M2 to do the adding, but not significantly so.
Just as a reference, heres the same code running under Microsofts XNA:
M1 called 5,000,000 times: 670ms
M2 called 5,000,000 times: 200ms
If i really wanted, i could increase the speed of Matrix.Add(Matrix,Matrix) by writing the adding logic in there aswell, but i don't really want to do that. If you want performance, you'll use the Add(ref,ref,out) option.
The before and after code can be seen here
I started working on Mono.XNA today. For those of you that don't know what it is, it's a cross platform implementation of the Microsoft XNA framework. So in a good few months, it should be possible to write a game once and then play it on MacOS, Windows, Linux, Xbox 360 and if you're really lucky, the PS3 aswell.
At the moment i'm just getting up to speed on the status of things. There's been a little bit of implementation done, and a lot of class stubbing. My aim over the next few days is to run some tools over both the Mono.XNA libs and the Microsoft.XNA libs and start creating a chart of what has been stubbed, what has been implemented and what hasn't been touched yet. This will help both existing devs and new devs figure out what's going on.
I'm just going to finish on one important note which came to my attention when looking at some of the Mono.XNA implemented classes.
String arithmetic is bad!
I came across the following (single) line of code in the ToString() method of the matrix class. While i have to admit, it was technically right, i just had to get rid of it asap. Here's the line:
return ("{ " + string.Format(info1, "{{M11:{0} M12:{1} M13:{2} M14:{3}}} ", new object[] { this.M11.ToString(info1), this.M12.ToString(info1), this.M13.ToString(info1), this.M14.ToString(info1) }) + string.Format(info1, "{{M21:{0} M22:{1} M23:{2} M24:{3}}} ", new object[] { this.M21.ToString(info1), this.M22.ToString(info1), this.M23.ToString(info1), this.M24.ToString(info1) }) + string.Format(info1, "{{M31:{0} M32:{1} M33:{2} M34:{3}}} ", new object[] { this.M31.ToString(info1), this.M32.ToString(info1), this.M33.ToString(info1), this.M34.ToString(info1) }) + string.Format(info1, "{{M41:{0} M42:{1} M43:{2} M44:{3}}} ", new object[] { this.M41.ToString(info1), this.M42.ToString(info1), this.M43.ToString(info1), this.M44.ToString(info1) }) + "}");
Yes, that huge block of code was written in one single line. Now, the main problem with this code is not the fact that it was written in one line, but that the amount of strings and objects generated is HUGE. Far beyond what is needed.
Let me dissect it in a little more detail. As soon as that long line of code is hit, it generates (by my count) 24 instances of the string class and 4 object arrays. Now, as strings are immutable, every time you "add" a string, what happens is a brand new string is created in memory and the old string is dumped, waiting to be garbage collected. So, once you take the string.Format() calls into account, you have a sizeable amount of strings being created per call. The overhead in this is massive!
Now, what should've been done is a StringBuilder should've been used. This would have cut the number of string instances created right down to just 1 per call, along with a single instance of the stringbuilder class.
So lets whip out the benchmarking utils and prove my point.
Original Method:
With the original method being called 10,000 times we had the following stats from my profiler:
Allocated bytes: 21,699,068
Relocated bytes: 17,864
Final Heap bytes: 897,800
This method allocated a whopping 2.11 kB of memory per call to Matrix.ToString(), give or take. That's a *lot* of memory when all you want to create is a 100-150 byte string! The execution time was approximately 4.41 seconds.
StringBuilder Method:
I changed to code to use a StringBuilder with default capacity of 140 bytes and called it 10,000 times. This had the following stats:
Allocated bytes: 6,479,100
Relocated bytes: 8,764
Final Heap bytes: 254,218
As you can see, this method reduced memory allocations by 66% straight off. The average memory allocation per call to Matrix.ToString() is now 0.630kB. Final heap wa reduced from 897kB to a mere 254kB, a 72% reduction in the heap size. The execution time was 2.58 seconds, that's nearly 50% faster. That change took me about 3 minutes to make (once i created an NUnit test to verify that the existing code was right before i ripped it apart ;) ).
The lesson for today, when creating strings, use the StringBuilder class. It helps performance hugely.
At the moment i'm just getting up to speed on the status of things. There's been a little bit of implementation done, and a lot of class stubbing. My aim over the next few days is to run some tools over both the Mono.XNA libs and the Microsoft.XNA libs and start creating a chart of what has been stubbed, what has been implemented and what hasn't been touched yet. This will help both existing devs and new devs figure out what's going on.
I'm just going to finish on one important note which came to my attention when looking at some of the Mono.XNA implemented classes.
String arithmetic is bad!
I came across the following (single) line of code in the ToString() method of the matrix class. While i have to admit, it was technically right, i just had to get rid of it asap. Here's the line:
return ("{ " + string.Format(info1, "{{M11:{0} M12:{1} M13:{2} M14:{3}}} ", new object[] { this.M11.ToString(info1), this.M12.ToString(info1), this.M13.ToString(info1), this.M14.ToString(info1) }) + string.Format(info1, "{{M21:{0} M22:{1} M23:{2} M24:{3}}} ", new object[] { this.M21.ToString(info1), this.M22.ToString(info1), this.M23.ToString(info1), this.M24.ToString(info1) }) + string.Format(info1, "{{M31:{0} M32:{1} M33:{2} M34:{3}}} ", new object[] { this.M31.ToString(info1), this.M32.ToString(info1), this.M33.ToString(info1), this.M34.ToString(info1) }) + string.Format(info1, "{{M41:{0} M42:{1} M43:{2} M44:{3}}} ", new object[] { this.M41.ToString(info1), this.M42.ToString(info1), this.M43.ToString(info1), this.M44.ToString(info1) }) + "}");
Yes, that huge block of code was written in one single line. Now, the main problem with this code is not the fact that it was written in one line, but that the amount of strings and objects generated is HUGE. Far beyond what is needed.
Let me dissect it in a little more detail. As soon as that long line of code is hit, it generates (by my count) 24 instances of the string class and 4 object arrays. Now, as strings are immutable, every time you "add" a string, what happens is a brand new string is created in memory and the old string is dumped, waiting to be garbage collected. So, once you take the string.Format() calls into account, you have a sizeable amount of strings being created per call. The overhead in this is massive!
Now, what should've been done is a StringBuilder should've been used. This would have cut the number of string instances created right down to just 1 per call, along with a single instance of the stringbuilder class.
So lets whip out the benchmarking utils and prove my point.
Original Method:
With the original method being called 10,000 times we had the following stats from my profiler:
Allocated bytes: 21,699,068
Relocated bytes: 17,864
Final Heap bytes: 897,800
This method allocated a whopping 2.11 kB of memory per call to Matrix.ToString(), give or take. That's a *lot* of memory when all you want to create is a 100-150 byte string! The execution time was approximately 4.41 seconds.
StringBuilder Method:
I changed to code to use a StringBuilder with default capacity of 140 bytes and called it 10,000 times. This had the following stats:
Allocated bytes: 6,479,100
Relocated bytes: 8,764
Final Heap bytes: 254,218
As you can see, this method reduced memory allocations by 66% straight off. The average memory allocation per call to Matrix.ToString() is now 0.630kB. Final heap wa reduced from 897kB to a mere 254kB, a 72% reduction in the heap size. The execution time was 2.58 seconds, that's nearly 50% faster. That change took me about 3 minutes to make (once i created an NUnit test to verify that the existing code was right before i ripped it apart ;) ).
The lesson for today, when creating strings, use the StringBuilder class. It helps performance hugely.
Monday, December 18, 2006
There's been some interesting events in the P2P world recently.
On the 8th of December it was announced that uTorrent (probably the best bittorrent client around for windows, although closed source) had been bought by BitTorrent Inc. As a direct result of uTorrent being bought over and in the hands of the "enemy" (RIAA, MPAA etc), a lot of trackers are banning the use of uTorrent. This means that if you want to download anything off that tracker, you now cannot use uTorrent. One of the highly recommend options is Azureus, which as good as it may be, is also extremely bloated. Whereas uTorrent can download away with as little as 2 megs of ram, Azureus demands a minimum of 50 megs these days.
Personally, i think that this is a bit over the top. Banning the best client i've ever used simply because it has a new owner, BitTorrent inc, is a bit over the top. It's always possible that this decision will be changed in the future, but the odds are slim. Farewell to the best client ever.
On the 8th of December it was announced that uTorrent (probably the best bittorrent client around for windows, although closed source) had been bought by BitTorrent Inc. As a direct result of uTorrent being bought over and in the hands of the "enemy" (RIAA, MPAA etc), a lot of trackers are banning the use of uTorrent. This means that if you want to download anything off that tracker, you now cannot use uTorrent. One of the highly recommend options is Azureus, which as good as it may be, is also extremely bloated. Whereas uTorrent can download away with as little as 2 megs of ram, Azureus demands a minimum of 50 megs these days.
Personally, i think that this is a bit over the top. Banning the best client i've ever used simply because it has a new owner, BitTorrent inc, is a bit over the top. It's always possible that this decision will be changed in the future, but the odds are slim. Farewell to the best client ever.
Tuesday, December 12, 2006
One down, 5 to go.
My hardest (or maybe second hardest :p ) exam is now over. Think of differential equations more complex than anything you've seen before (unless you studied pure maths in college). Those are the kind of things i battled with earlier today. The questions were (unfortunately) the kind of ones that actually require you to think before even attempting an answer. It's not so simple as looking at a question and instantly knowing the way to solve it. It didn't help that the course is new and we had no past papers to look at for guidance. Anyway, it's over now!
I have another one tomorrow, tis maths aswell, but thankfully it's only vector calculus. Calculus and vectors. Vectors and calculus. It's a nice combination really. I never found either topic particularly difficult, so when combined they're not too bad!
I have 4 exams after maths: one on friday, one on saturday, one on monday and the last one on tuesday. The only tough one out of the lot is the monday exam, so that's gonna need a fair bit of work. Still, it'll all be over in 7 days. I can't wait for the christmas break.
My hardest (or maybe second hardest :p ) exam is now over. Think of differential equations more complex than anything you've seen before (unless you studied pure maths in college). Those are the kind of things i battled with earlier today. The questions were (unfortunately) the kind of ones that actually require you to think before even attempting an answer. It's not so simple as looking at a question and instantly knowing the way to solve it. It didn't help that the course is new and we had no past papers to look at for guidance. Anyway, it's over now!
I have another one tomorrow, tis maths aswell, but thankfully it's only vector calculus. Calculus and vectors. Vectors and calculus. It's a nice combination really. I never found either topic particularly difficult, so when combined they're not too bad!
I have 4 exams after maths: one on friday, one on saturday, one on monday and the last one on tuesday. The only tough one out of the lot is the monday exam, so that's gonna need a fair bit of work. Still, it'll all be over in 7 days. I can't wait for the christmas break.
Monday, December 04, 2006
So my exams are starting in less than 10 days. I'm slowly turning into an eat-sleep-study zombie. The pressure is on to cram as much as possible into my brain within the next week or two so i can do amazingly well... or at least thats what i tell myself. On one hand, the exams are only worth 15% of my final degree, so i don't have to perform amazingly well in these to walk out with a good degree next year, but any marks i pick up now remove some of the pressure from next year. It'd be nice going into final year knowing that i've already picked up 20+% of my final degree!
It's right about now that I begin to regret skipping all those lectures despite promising myself i wouldn't do that this year. I also wish i had finished off all those problem sheets a few weeks ago, but that never happened ;) Ah well, sure what's the worst that can happen! I have 9 days, i have coffee, what more do i need... except for more time ;)
On the plus side i've begun sticking monotorrent through an extensive regime of testing. I've transferred several gigs with it over the last few days/weeks and fixed a lot of little (and not so little) bugs. But the big test is when hundreds of people start using it and submitting bug reports. That'll be a great day ;) I just have to wait til after those blasted exams.
It's right about now that I begin to regret skipping all those lectures despite promising myself i wouldn't do that this year. I also wish i had finished off all those problem sheets a few weeks ago, but that never happened ;) Ah well, sure what's the worst that can happen! I have 9 days, i have coffee, what more do i need... except for more time ;)
On the plus side i've begun sticking monotorrent through an extensive regime of testing. I've transferred several gigs with it over the last few days/weeks and fixed a lot of little (and not so little) bugs. But the big test is when hundreds of people start using it and submitting bug reports. That'll be a great day ;) I just have to wait til after those blasted exams.
Sunday, November 26, 2006
When profiling MonoTorrent (under MS.NET, i haven't managed to get profiling under mono working yet. That should lead to a nice comparison), i noticed that about 85% (or more) of my ongoing allocations are due to the 100's of asynchronous sending and receiving methods that i fire every second. For example, if i set my download rate to 400kB/sec, there would be ~200 socket.BeginReceive calls every second. Add in a few BeginSend's and that's quite a lot of calls being fired.
Now, the thing is that when each of those operations finishes there is a bit of managed overhead to allow my callback to be executed (such as System.Net.Sockets.OverlappedAsyncResult, System.Threading.ExecutionContext etc). Now, these allocations are all pretty short term, 95% of them will be cleared up during the next garbage collection. The only ones that won't be cleared up are ones for connections that are running at that moment in time.
Now, it struck me then that wouldn't it be nice if there was a way of detecting "temporary" variables and being able to deallocate them immediately when they go out of scope. This way some items could be destroyed practically immediately after a method ends which reduces the work the GC has to do and reduces the memory overhead of having objects hanging around that arent going to be used more than once.
Take this method for an example:
public void Example()
{
MyObject a = new MyObject(15);
a.DoACalculation();
Console.WriteLine(a.ResultFromCalculation);
return;
}
Now, it should be possible to do a scan and see that an object 'a' is instantiated, then it is only used to calculate a value (for example 15*15+15) and then print that result to the console. A reference to the object never leaves the scope of the method, therefore the object could be classified as a "Fast GC Object" and could be deallocated as soon as the "return" statement is hit.
Also, take a look at this.
public void Example2()
{
using(MainForm form = new MainForm())
form.ShowModal();
return;
}
In this case, *everything* to do with that form could be GC'ed as soon as the return statement is hit. These "Fast GC" objects would never need to be tracked by the GC as such as it is known at the JIT stage when each object will be allocated and when each object will be destroyed.
Now, i've been told that this idea is nothing new (and i'm not surprised). The art of deciding what objects can be GC'ed fast is known as Escape Analysis. The question is, what is the real world benefit for this kind of Garbage Collection. Does it provide an appreciable difference to overall memory usage? Does it reduce time spent in Garbage Collection? Is it exceptionally difficult to implement? Can the JIT be modified to generate this kind of code?
It should be possible to do a mockup to test the theory without changing anything in the Mono runtime. It should be possible to take the bytecode for any .NET application and run a program on it which will check which methods have objects which can be fast GC'ed. Once this data has been stored, the application being tested can be run with a profiler attached which just monitors how many times each method is hit during normal use.
With the knowledge of how many times each method is being hit and which objects are able to be fast GC'ed it should be possible to calculate what the benefit would be to use this new method of garbage collection. A statistic like 50% of all object allocations could be changed to be "Fast GC Objects" would be nice. Then again, if the realworld statistics said that 95% of applications would have less than 5% of their objects suitable for "Fast GC" would mean this method is near useless.
Now, the thing is that when each of those operations finishes there is a bit of managed overhead to allow my callback to be executed (such as System.Net.Sockets.OverlappedAsyncResult, System.Threading.ExecutionContext etc). Now, these allocations are all pretty short term, 95% of them will be cleared up during the next garbage collection. The only ones that won't be cleared up are ones for connections that are running at that moment in time.
Now, it struck me then that wouldn't it be nice if there was a way of detecting "temporary" variables and being able to deallocate them immediately when they go out of scope. This way some items could be destroyed practically immediately after a method ends which reduces the work the GC has to do and reduces the memory overhead of having objects hanging around that arent going to be used more than once.
Take this method for an example:
public void Example()
{
MyObject a = new MyObject(15);
a.DoACalculation();
Console.WriteLine(a.ResultFromCalculation);
return;
}
Now, it should be possible to do a scan and see that an object 'a' is instantiated, then it is only used to calculate a value (for example 15*15+15) and then print that result to the console. A reference to the object never leaves the scope of the method, therefore the object could be classified as a "Fast GC Object" and could be deallocated as soon as the "return" statement is hit.
Also, take a look at this.
public void Example2()
{
using(MainForm form = new MainForm())
form.ShowModal();
return;
}
In this case, *everything* to do with that form could be GC'ed as soon as the return statement is hit. These "Fast GC" objects would never need to be tracked by the GC as such as it is known at the JIT stage when each object will be allocated and when each object will be destroyed.
Now, i've been told that this idea is nothing new (and i'm not surprised). The art of deciding what objects can be GC'ed fast is known as Escape Analysis. The question is, what is the real world benefit for this kind of Garbage Collection. Does it provide an appreciable difference to overall memory usage? Does it reduce time spent in Garbage Collection? Is it exceptionally difficult to implement? Can the JIT be modified to generate this kind of code?
It should be possible to do a mockup to test the theory without changing anything in the Mono runtime. It should be possible to take the bytecode for any .NET application and run a program on it which will check which methods have objects which can be fast GC'ed. Once this data has been stored, the application being tested can be run with a profiler attached which just monitors how many times each method is hit during normal use.
With the knowledge of how many times each method is being hit and which objects are able to be fast GC'ed it should be possible to calculate what the benefit would be to use this new method of garbage collection. A statistic like 50% of all object allocations could be changed to be "Fast GC Objects" would be nice. Then again, if the realworld statistics said that 95% of applications would have less than 5% of their objects suitable for "Fast GC" would mean this method is near useless.
Saturday, November 18, 2006
With less than a month to go to my christmas exams, my coding time as been reduced to zero. Pretty much everything else has been put on standby now (including writing content for the website) until the exams are over.
Everything is pretty much ready for a release i think, but i need to run a few tests first to make sure. Then it's beta testing time.
I've also received an interesting email yesterday. Someone has taken the time to rejig the code so that the client library will now run on the .NET compact framework. This means that you can now download .torrents on your smart phone, or whatever portable device you have that supports the .net Compact framework. So now not only can monotorrent run on all your favourite desktop OS's, but now it can be run on some of your favourite portable machines too.
Also with the ability to put mono on embedded devices, it's quite possible that if an interested party could be found, monotorrent could be stuck on a settop box on top of your television and could stream content directly to a HD for later viewing. The possibilities are endless!
Everything is pretty much ready for a release i think, but i need to run a few tests first to make sure. Then it's beta testing time.
I've also received an interesting email yesterday. Someone has taken the time to rejig the code so that the client library will now run on the .NET compact framework. This means that you can now download .torrents on your smart phone, or whatever portable device you have that supports the .net Compact framework. So now not only can monotorrent run on all your favourite desktop OS's, but now it can be run on some of your favourite portable machines too.
Also with the ability to put mono on embedded devices, it's quite possible that if an interested party could be found, monotorrent could be stuck on a settop box on top of your television and could stream content directly to a HD for later viewing. The possibilities are endless!
Tuesday, November 07, 2006
So i have a few things to mention today.
I've very kindly been offered some hosting and a free webpage created for MonoTorrent on the condition that i continue developing the library. That's something i think i can manage ;) So in a week or two, i'll be posting a link to the new site along with one or two exciting announcements. I bet ye can hardly wait ;)
Development is still going well on MonoTorrent. I implemented EndGame mode today (which had completely slipped my mind as i was either working on local torrents, or just testing briefly on large torrents so i never reached the final few % of the download). This means that the final stages of downloading a torrent will go a *lot* faster now. Previously the last few percent would either never finish (due to deadlock condition mentioned below) or finished really slowly.
I also fixed a problem where i'd request a piece off a peer, but they'd never send the piece i requested. This meant that they stayed in a limbo where i thought i had pending requests off them, but they had no intention of fulfilling those requests. Hence no other peer would be able to request those pieces.
For those of you interested in developing for the library, i've included a new Class Description document in the SVN which gives a *very* brief description of what each class does. I'll do my best to update the XML comments within the classes aswell at some stage. But i promise nothing ;)
Once again, be ready for a few surprise announcements over the next week or so. It'll (hopefully) be worth the wait.
I've very kindly been offered some hosting and a free webpage created for MonoTorrent on the condition that i continue developing the library. That's something i think i can manage ;) So in a week or two, i'll be posting a link to the new site along with one or two exciting announcements. I bet ye can hardly wait ;)
Development is still going well on MonoTorrent. I implemented EndGame mode today (which had completely slipped my mind as i was either working on local torrents, or just testing briefly on large torrents so i never reached the final few % of the download). This means that the final stages of downloading a torrent will go a *lot* faster now. Previously the last few percent would either never finish (due to deadlock condition mentioned below) or finished really slowly.
I also fixed a problem where i'd request a piece off a peer, but they'd never send the piece i requested. This meant that they stayed in a limbo where i thought i had pending requests off them, but they had no intention of fulfilling those requests. Hence no other peer would be able to request those pieces.
For those of you interested in developing for the library, i've included a new Class Description document in the SVN which gives a *very* brief description of what each class does. I'll do my best to update the XML comments within the classes aswell at some stage. But i promise nothing ;)
Once again, be ready for a few surprise announcements over the next week or so. It'll (hopefully) be worth the wait.
Sunday, November 05, 2006
This is just a wild stab into the dark here, but i'm hoping my newfound fame (subtle promotion of monocast: http://www.mono-cast.com/?p=28) can find me someone with a few hours/days to spare who can throw together a website for me.
What i'm looking for is a nice, simple, easy to maintain website for MonoTorrent. Hosting i can sort out, i have the domain registered aswell, i just need content to put up! So if anyone would be interested in slapping together the following, that'd be great:
1) Homepage: Simple enough design, just a place where i can write announcements and stuff
2) A FAQ/Code Examples page
3) A page where i'll list different releases of the library.
4) A page where i can list all the features etc and mention licensing etc.
Like i said, nothing to fancy. So long as i can update things easily, i'll be happy. I just want something that's nice enough to look at and easy to browse. If anyone is interested in taking up the challange, give me a shout. I'd really appreciate it. Don't go writing anything without contacting me first, just to make sure that work isn't duplicated (or triplicated) and i can actually use the resulting code.
Thanks!
What i'm looking for is a nice, simple, easy to maintain website for MonoTorrent. Hosting i can sort out, i have the domain registered aswell, i just need content to put up! So if anyone would be interested in slapping together the following, that'd be great:
1) Homepage: Simple enough design, just a place where i can write announcements and stuff
2) A FAQ/Code Examples page
3) A page where i'll list different releases of the library.
4) A page where i can list all the features etc and mention licensing etc.
Like i said, nothing to fancy. So long as i can update things easily, i'll be happy. I just want something that's nice enough to look at and easy to browse. If anyone is interested in taking up the challange, give me a shout. I'd really appreciate it. Don't go writing anything without contacting me first, just to make sure that work isn't duplicated (or triplicated) and i can actually use the resulting code.
Thanks!
Saturday, November 04, 2006
I was off at a Muse concert earlier tonight. I have to say, it was brilliant! They (literally) blew me away! The lights and videos were amazing. The only bad thing i'd say is that Matt Belemy (the lead singer) doesn't really talk to the crowd at all. You'd be lucky to get a "hello dublin" out of him ;) But all in all, a good night!
Thursday, November 02, 2006
I finally got rate limiting pegged. Method 4 out of my last post with a few slight modifications was what finally worked for me, i knew i was onto a winner!
As i found out, relying directly on DownloadSpeed to implement rate limiting made it next to impossible to get accurate rate limiting, but without using the current DownloadSpeed it's impossible to get accurate rate limiting. A bit of a conundrum, isn't it. So, the solution is to use what is best described as a feedback loop a.k.a. a Proportional Intergral controller for those of you not studying electronic engineering ;)
My final algorithm works as follows:
1) Each chunk of data i send is (ideally) exactly 2kB in size.
2) Every second i calculate the error rate in my download speed. The Error rate is the difference between the download speed i want and what i'm currently downloading at.
int errorRateDown = maxDownloadSpeed - actualDownloadSpeed;
3) I also have stored the error rate from the previous second which i then use to get a weighted average. This average is weighted to give the error rate from the last second more importance than the error rate in the current second.
int averageErrorRateDown = (int)(0.4 * errorRateDown + 0.6 * this.SavedErrorRateDown);
4) Finally, to calculate the number of 2kB blocks i should be transferring this second, i just run the simple calculation:
int numberOfBlocksToRequest = (maxDownloadSpeed + this.averageErrorRateDown) / ConnectionManager.ChunkLength;
As you can probably see, the closer i get to my requested download speed, the smaller and smaller averageErrorRateDown will get, thus reducing the number of blocks i request. If i'm downloading to slowly, averageErroRate will be a large positive number (increasing the number of blocks). If i download too fast, averageErrorRate will become a large negative number (decreasing the number of blocks).
Then every time i want to send a block, if numberOfBlocksToRequest is greater than zero, i decrement it by one and send the block. If numberOfBlocksToRequest is zero, i just hold the block in memory in a queue and as soon as i'm allowed, i'll send it. Obviously a FIFO queue is used ;)
The only issue with this method is that the size of the blocks i send aren't always exactly 2kB in size, so this method will always settle at a download rate just below the requested download rate. But that can be compensated for.
As i found out, relying directly on DownloadSpeed to implement rate limiting made it next to impossible to get accurate rate limiting, but without using the current DownloadSpeed it's impossible to get accurate rate limiting. A bit of a conundrum, isn't it. So, the solution is to use what is best described as a feedback loop a.k.a. a Proportional Intergral controller for those of you not studying electronic engineering ;)
My final algorithm works as follows:
1) Each chunk of data i send is (ideally) exactly 2kB in size.
2) Every second i calculate the error rate in my download speed. The Error rate is the difference between the download speed i want and what i'm currently downloading at.
int errorRateDown = maxDownloadSpeed - actualDownloadSpeed;
3) I also have stored the error rate from the previous second which i then use to get a weighted average. This average is weighted to give the error rate from the last second more importance than the error rate in the current second.
int averageErrorRateDown = (int)(0.4 * errorRateDown + 0.6 * this.SavedErrorRateDown);
4) Finally, to calculate the number of 2kB blocks i should be transferring this second, i just run the simple calculation:
int numberOfBlocksToRequest = (maxDownloadSpeed + this.averageErrorRateDown) / ConnectionManager.ChunkLength;
As you can probably see, the closer i get to my requested download speed, the smaller and smaller averageErrorRateDown will get, thus reducing the number of blocks i request. If i'm downloading to slowly, averageErroRate will be a large positive number (increasing the number of blocks). If i download too fast, averageErrorRate will become a large negative number (decreasing the number of blocks).
Then every time i want to send a block, if numberOfBlocksToRequest is greater than zero, i decrement it by one and send the block. If numberOfBlocksToRequest is zero, i just hold the block in memory in a queue and as soon as i'm allowed, i'll send it. Obviously a FIFO queue is used ;)
The only issue with this method is that the size of the blocks i send aren't always exactly 2kB in size, so this method will always settle at a download rate just below the requested download rate. But that can be compensated for.
Tuesday, October 31, 2006
Rate limiting: Not as simple as you might think
Firstly, some background info. Every socket.BeginReceive() i call downloads data in 2kB chunks. By receiving 2kB at a time, i can get more accurate download speeds recorded and (hopefully) more accurate rate limiting. Download speeds are averaged over 8 seconds with data recorded each second. This provides a resonably stable but accurate download rate. A torrents download speed is calculated by summing up the download speed of each active client.
Method 1:
while(torrentManager.DownloadSpeed() < this.MaxDownloadSpeed)
torrentManager.StartAPeerDownloading();
This method seems like it would be a good way to limit download speed, except it fails miserably in areas where there is high bandwidth available. I.e. in a LAN situation, due to the fact that i only update peer download speeds every second, if a LAN client could easily transfer 1-2MB in that second (call it second[0]), so if my rate limit was 100kB/sec, the client would then stop downloading chunks off all peers until the 8 second averaging period has passed, and so it thinks that download speed is 0. Then the cycle starts over again and the algorithm could request another 2 megabytes in the first second, and then be followed by an additional 8 seconds of nothing.
Method 2:
Keep a count of how many 2kB chunks i transfer per second: chunksCount;
At the end of every second, after i calculate the current download speed, i perform the following calculation:
downloadSpeed = torrentManager.DownloadSpeed();
// This is the difference in speed between what i'm currentl doig and what i should be doing.
// A negative number means i'm going to fast. If 20480 is returned, it means i'm 20kB/sec
// to slow
speedDifference = torrentManager.MaxDownloadSpeed - downloadSpeed;
// The number of additional chunks i need to download in order to reach my rate limiting
// target is the speedDifference / chunkSize. i.e. 20480 / 2048 = 10 chunks extra per second
chunksCount+= speedDifference / 2048;
This tells me how many chunks i need to send this (and every) second to reach my quota. So i can then run code like:
while(chunksSent++ < ChunksCount)
torrentManager.StartAPeerDownloading();
However this runs into problems that if i overshoot download speed (due to inaccurate MaxDownloadSpeed for the same conditions as mentioned in method 1) i end up with a hugely oscillating chunksCount. This algorithm suffers a similar problem to the one above in high bandwidth situations, but not to the same extent.
Method 3:
Similar to above, but with a slight twist.
Assume every chunk i try to download is exactly 2048 bytes (not always true). Therefore the "ideal" number of chunks to download a second is:
int idealNumberOfChunks = torrentManager.MaxDownloadSpeed/2048;
Then take a double called "multiplyAmount" and initially set it equal to 1.0.
What i do now is at the end of every second i do the following:
// I'm going to fast, so i need to reduce my multiply amount
if(torrentManager.DownloadSpeed > this.MaxDownloadSpeed)
multiplyAmount *= 0.95;
// I'm going to slow, i need to increase my multiply amount
else
multiplyAmount *= 1.05;
ChunksCount = idealNumberOfChunks * multiplyAmount;
Basically what i do at the end of every second is see if i'm going to slow or too fast. If i'm going to slow, i increase my multiply amount (which retains it's value between calls to my method). So if i'm consistantly too slow, my multiplyAmount will slowly increase from 1.0 right up until 5.0 (which is a hardcoded max for multiplyamount).
What this should result in is that the ChunksCount will initially start off equal to the idealNumberOfChunks but if i'm going too slow, it'll request more and more chunks above the ideal amount, but if i'm going to fast, it'll start requesting less and less chunks. Unfortunately this algorithm didn't really work either. It tends to go too fast, then too slowly, then too fast. This is caused by MultiplyAmount increasing and decreasing every second. But it is by far the best method so far (and the one i've currently left implemented).
Ratelimiting is definately not such a simple thing to do. Even keeping track of the DownloadSpeed is tricky, with my code occasionally running riot and calculating 100kB/sec when actual rate is 50kB/sec.
So if anyone has any ideas on how to implement some accurate ratelimiting, that'd be great! Or if my badly explained ideas don't make sense, ask me to explain it a bit better.
Firstly, some background info. Every socket.BeginReceive() i call downloads data in 2kB chunks. By receiving 2kB at a time, i can get more accurate download speeds recorded and (hopefully) more accurate rate limiting. Download speeds are averaged over 8 seconds with data recorded each second. This provides a resonably stable but accurate download rate. A torrents download speed is calculated by summing up the download speed of each active client.
Method 1:
while(torrentManager.DownloadSpeed() < this.MaxDownloadSpeed)
torrentManager.StartAPeerDownloading();
This method seems like it would be a good way to limit download speed, except it fails miserably in areas where there is high bandwidth available. I.e. in a LAN situation, due to the fact that i only update peer download speeds every second, if a LAN client could easily transfer 1-2MB in that second (call it second[0]), so if my rate limit was 100kB/sec, the client would then stop downloading chunks off all peers until the 8 second averaging period has passed, and so it thinks that download speed is 0. Then the cycle starts over again and the algorithm could request another 2 megabytes in the first second, and then be followed by an additional 8 seconds of nothing.
Method 2:
Keep a count of how many 2kB chunks i transfer per second: chunksCount;
At the end of every second, after i calculate the current download speed, i perform the following calculation:
downloadSpeed = torrentManager.DownloadSpeed();
// This is the difference in speed between what i'm currentl doig and what i should be doing.
// A negative number means i'm going to fast. If 20480 is returned, it means i'm 20kB/sec
// to slow
speedDifference = torrentManager.MaxDownloadSpeed - downloadSpeed;
// The number of additional chunks i need to download in order to reach my rate limiting
// target is the speedDifference / chunkSize. i.e. 20480 / 2048 = 10 chunks extra per second
chunksCount+= speedDifference / 2048;
This tells me how many chunks i need to send this (and every) second to reach my quota. So i can then run code like:
while(chunksSent++ < ChunksCount)
torrentManager.StartAPeerDownloading();
However this runs into problems that if i overshoot download speed (due to inaccurate MaxDownloadSpeed for the same conditions as mentioned in method 1) i end up with a hugely oscillating chunksCount. This algorithm suffers a similar problem to the one above in high bandwidth situations, but not to the same extent.
Method 3:
Similar to above, but with a slight twist.
Assume every chunk i try to download is exactly 2048 bytes (not always true). Therefore the "ideal" number of chunks to download a second is:
int idealNumberOfChunks = torrentManager.MaxDownloadSpeed/2048;
Then take a double called "multiplyAmount" and initially set it equal to 1.0.
What i do now is at the end of every second i do the following:
// I'm going to fast, so i need to reduce my multiply amount
if(torrentManager.DownloadSpeed > this.MaxDownloadSpeed)
multiplyAmount *= 0.95;
// I'm going to slow, i need to increase my multiply amount
else
multiplyAmount *= 1.05;
ChunksCount = idealNumberOfChunks * multiplyAmount;
Basically what i do at the end of every second is see if i'm going to slow or too fast. If i'm going to slow, i increase my multiply amount (which retains it's value between calls to my method). So if i'm consistantly too slow, my multiplyAmount will slowly increase from 1.0 right up until 5.0 (which is a hardcoded max for multiplyamount).
What this should result in is that the ChunksCount will initially start off equal to the idealNumberOfChunks but if i'm going too slow, it'll request more and more chunks above the ideal amount, but if i'm going to fast, it'll start requesting less and less chunks. Unfortunately this algorithm didn't really work either. It tends to go too fast, then too slowly, then too fast. This is caused by MultiplyAmount increasing and decreasing every second. But it is by far the best method so far (and the one i've currently left implemented).
Ratelimiting is definately not such a simple thing to do. Even keeping track of the DownloadSpeed is tricky, with my code occasionally running riot and calculating 100kB/sec when actual rate is 50kB/sec.
So if anyone has any ideas on how to implement some accurate ratelimiting, that'd be great! Or if my badly explained ideas don't make sense, ask me to explain it a bit better.
Monday, October 30, 2006
Yet another piece of good news, thanks to the patch by Kevin, a little bit of hacking and some help from the #mono channel, piotrs' GUI is now compiling and starting up.
Ok, so there are a few minor (note: When i say "minor" i mean the whole GUI vanishing without a trace before your eyes ;)) bugs in it which i have yet to work through, but all going well i'll have them ironed out in a few days. But i am extremely tempted to rip apart the existing design (which seems a little overcomplicated) and start afresh using it as a template. It looks nice enough (if basic), but far too much info is hardcoded. For example, there's no way to choose where to save a .torrent to! They'll always go to your $personal$ folder (i.e. my documents on windows).
So all going well i'll have a Pre-Beta 1 release coming out soon of the monotorrent client library plus GUI. The only major thing left to do is re-implement my RateLimiting code. While the previous code worked, it had too much of a dependancy on timers, and so created artificial limits on download speed. I have a few ideas, but im not quite sure how it'll all pan out.
I'll leave ye with a few screenshots:
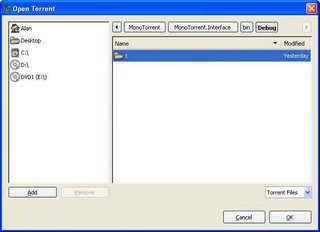
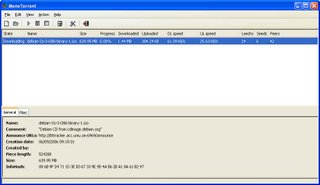

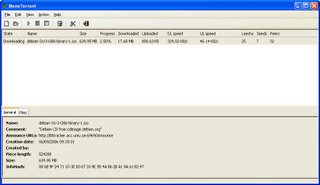
Ok, so there are a few minor (note: When i say "minor" i mean the whole GUI vanishing without a trace before your eyes ;)) bugs in it which i have yet to work through, but all going well i'll have them ironed out in a few days. But i am extremely tempted to rip apart the existing design (which seems a little overcomplicated) and start afresh using it as a template. It looks nice enough (if basic), but far too much info is hardcoded. For example, there's no way to choose where to save a .torrent to! They'll always go to your $personal$ folder (i.e. my documents on windows).
So all going well i'll have a Pre-Beta 1 release coming out soon of the monotorrent client library plus GUI. The only major thing left to do is re-implement my RateLimiting code. While the previous code worked, it had too much of a dependancy on timers, and so created artificial limits on download speed. I have a few ideas, but im not quite sure how it'll all pan out.
I'll leave ye with a few screenshots:
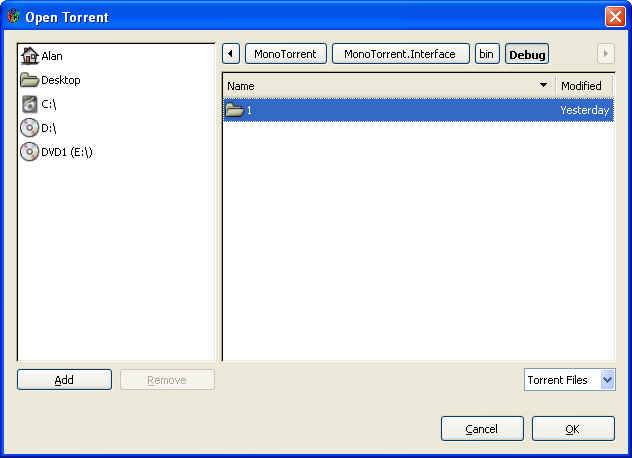

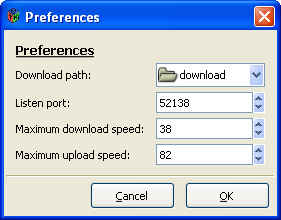

Sunday, October 29, 2006
Well well well.
MonoTorrent got a speed boost.
Download speeds have gone from ~ 30kB/sec to ~4.5MB/sec (and probably faster!). The only bad thing is that i've had to disable my rate limiting code completely until i can come up with a way of writing the code that won't kill download speeds. It's not so simple!
Memory usage is down to single digit figures aswell, less than 10 megabytes! So it looks like i well achieved my aim of creating a cross platform client that uses less than 1/3 the ram that Azureus uses. The only thing i need now is a nice GUI for it. I got a patch for the GUI that was created during the summer, and i hacked a little at it myself, so now it compiles. I'll take a more indepth look at it later on and see if i can nice it up a bit (and reduce it's memory usage, if possible).
Just a little eye candy for ye to enjoy: http://picasaweb.google.com/alan.mcgovern/ There's a few images up there where i screenshotted download speed/upload speed and memory usage.
DebianTorrent: This is a real world torrent. So performance in this test is exactly how you'd expect in real life (i'm on a 3meg connection btw).
DownloadingMonoTorrent: I used both Azureus and uTorrent as "seeders" on my local machine to see how fast monotorrent would download. Azureus maxes out at ~1.6 MB/sec upload, uTorrent maxes out at about 3-3.2MB/sec, so i don't really know the limits of my code ;) My best guesstimate based on the way i've coded the logic sections would be a theoretical max of: pieceLength*2*(1000/25) kB/sec. i.e. i can request all the blocks for two pieces every 25 miliseconds. If my maths is right, that's approximately a limit of 20MB/sec per peer. The library should be able to upload as fast as your harddrive can seek ;)
UploadingMonoTorrent: I started monotorrent off at 100% and then set Azureus and uTorrent to start at 0% and leech. Bear in mind there would be a little crosstalk between Azureus and uTorrent. They did share some information between themselves.
MonoTorrent got a speed boost.
Download speeds have gone from ~ 30kB/sec to ~4.5MB/sec (and probably faster!). The only bad thing is that i've had to disable my rate limiting code completely until i can come up with a way of writing the code that won't kill download speeds. It's not so simple!
Memory usage is down to single digit figures aswell, less than 10 megabytes! So it looks like i well achieved my aim of creating a cross platform client that uses less than 1/3 the ram that Azureus uses. The only thing i need now is a nice GUI for it. I got a patch for the GUI that was created during the summer, and i hacked a little at it myself, so now it compiles. I'll take a more indepth look at it later on and see if i can nice it up a bit (and reduce it's memory usage, if possible).
Just a little eye candy for ye to enjoy: http://picasaweb.google.com/alan.mcgovern/ There's a few images up there where i screenshotted download speed/upload speed and memory usage.
DebianTorrent: This is a real world torrent. So performance in this test is exactly how you'd expect in real life (i'm on a 3meg connection btw).
DownloadingMonoTorrent: I used both Azureus and uTorrent as "seeders" on my local machine to see how fast monotorrent would download. Azureus maxes out at ~1.6 MB/sec upload, uTorrent maxes out at about 3-3.2MB/sec, so i don't really know the limits of my code ;) My best guesstimate based on the way i've coded the logic sections would be a theoretical max of: pieceLength*2*(1000/25) kB/sec. i.e. i can request all the blocks for two pieces every 25 miliseconds. If my maths is right, that's approximately a limit of 20MB/sec per peer. The library should be able to upload as fast as your harddrive can seek ;)
UploadingMonoTorrent: I started monotorrent off at 100% and then set Azureus and uTorrent to start at 0% and leech. Bear in mind there would be a little crosstalk between Azureus and uTorrent. They did share some information between themselves.
Wednesday, October 25, 2006
Since the SoC ended i've been hard at work at both college and life, so coding time has been severely reduced. Nonetheless i have managed a few good things and a few bad things for the library ;)
For the good things: I now have memory usage in the range of 10-13 megabytes with 3 torrents running simultaenously. There's still one or two more optimisations that i have left to try. I'm at the level where calling DateTime.Now is responsible for 30% of my ongoing allocations! Ok, so i am calling it ~ 400 times a second, but that has nothing to do with it ;) Bug fixes have been flying in and most importantly (imo) i have received my first patches from other people! Yes, other people have sent me patches for MonoTorrent, amazing stuff.
The bad things: I've found some serious bugs in MS.NET which were the root cause behind the mysterious freezing i used to get in client library. What happens is that sometimes an Asynchronous call to socket.BeginReceive would actually be completed synchronously. "But thats good, it saves the computer from starting up another thead" you might think, but you'd be wrong!
My code was built on the fact that an asynchronous call was asynchronous. So, the problem is this. When dealing with multithreaded code you have to make sure that a different thread doesnt modify/delete data that your main thread is working on. To do this, you must put a "lock" on the item you're working on. Then when Thread 2 sees the lock, it wont do anything until Thread1 is finished and releases its' lock. Problems arise when Thread1 locks on item A and wants to lock onto B while Thread2 already has a lock on B but wants a lock on A. In this scenario, neither thread can go forward and so your application locks up.
Unfortunately this is exactly what happens when my socket call is completed synchronously. Thank microsoft for such a nice undocumented feature.
Finally in bad news: Download speeds are gone to crap. I'm going to have to remove my rate limiting code and get everything working hunky dorey before i reimplement rate limiting. My whole locking structure needs to be reviewed in light of the above mentioned bug. I've put in a temporary fix, but a side effect of it is to make downloading go pretty damn slowly.
Great fun all round ;)
Alan.
For the good things: I now have memory usage in the range of 10-13 megabytes with 3 torrents running simultaenously. There's still one or two more optimisations that i have left to try. I'm at the level where calling DateTime.Now is responsible for 30% of my ongoing allocations! Ok, so i am calling it ~ 400 times a second, but that has nothing to do with it ;) Bug fixes have been flying in and most importantly (imo) i have received my first patches from other people! Yes, other people have sent me patches for MonoTorrent, amazing stuff.
The bad things: I've found some serious bugs in MS.NET which were the root cause behind the mysterious freezing i used to get in client library. What happens is that sometimes an Asynchronous call to socket.BeginReceive would actually be completed synchronously. "But thats good, it saves the computer from starting up another thead" you might think, but you'd be wrong!
My code was built on the fact that an asynchronous call was asynchronous. So, the problem is this. When dealing with multithreaded code you have to make sure that a different thread doesnt modify/delete data that your main thread is working on. To do this, you must put a "lock" on the item you're working on. Then when Thread 2 sees the lock, it wont do anything until Thread1 is finished and releases its' lock. Problems arise when Thread1 locks on item A and wants to lock onto B while Thread2 already has a lock on B but wants a lock on A. In this scenario, neither thread can go forward and so your application locks up.
Unfortunately this is exactly what happens when my socket call is completed synchronously. Thank microsoft for such a nice undocumented feature.
Finally in bad news: Download speeds are gone to crap. I'm going to have to remove my rate limiting code and get everything working hunky dorey before i reimplement rate limiting. My whole locking structure needs to be reviewed in light of the above mentioned bug. I've put in a temporary fix, but a side effect of it is to make downloading go pretty damn slowly.
Great fun all round ;)
Alan.
Subscribe to:
Posts (Atom)